


Well its looks I really getting fond of writing blogs. I think everyone should at least give a try writing blogs once :)
Today I am going to study some of the Dataflow transformations, MERGE, MERGE JOIN, and UNION ALL.
Yes the first question any SQL SERVER developer can ask is, these operations can very well be done in T-SQL query, Why using it in SSIS?, well the answer is, T-SQL can be used only when you are working with data which resides in SQL SEVER Tables, but what if the data is coming from different database itself like ORACLE or MYSQL or Flat File or XML or EXCEL.
Let’s take it one by one each transformation, the post also covers differences, which are actually common questions, in any SSIS interviews.
Rather than reinventing the wheel, I am taking the text from MSDN for providing the description of each transformation which I found covering everything J
MERGE:
The Merge transformation combines two sorted datasets into a single dataset. The rows from each dataset are inserted into the output based on values in their key columns.
By including the Merge transformation in a data flow, you can perform the following tasks:
The Merge transformation is similar to the Union All transformations. Use the Union All transformation instead of the Merge transformation in the following situations:
Well here is the example..here we are taking input from two different sql server databases and merging them into a flatfile.
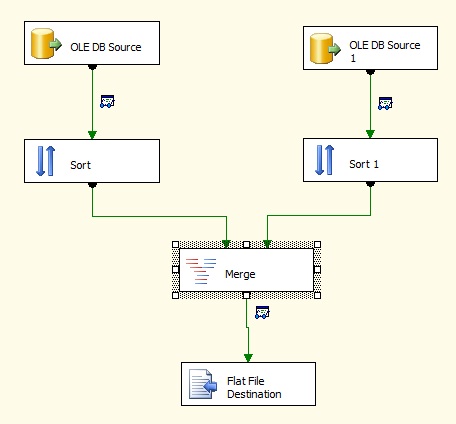
And here is what we need to set in Merge Transformation properties

This transformation is pretty simple and straight forward.
MERGE JOIN: The Merge Join transformation provides an output that is generated by joining two sorted datasets using a FULL, LEFT, or INNER join. For example, you can use a LEFT join to join a table that includes product information with a table that lists the country/region in which a product was manufactured. The result is a table that lists all products and their country/region of origin. For more information, see Using Joins.
You can configure the Merge Join transformation in the following ways:
This transformation has two inputs and one output. It does not support an error output.
Here is the same example with merge join..
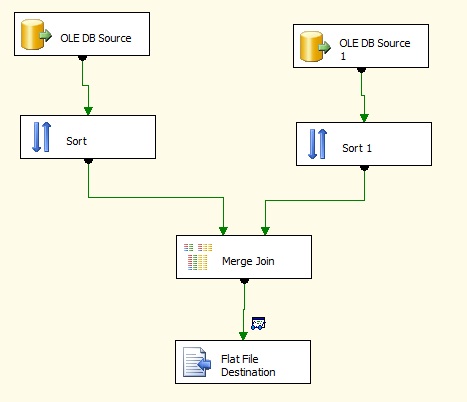
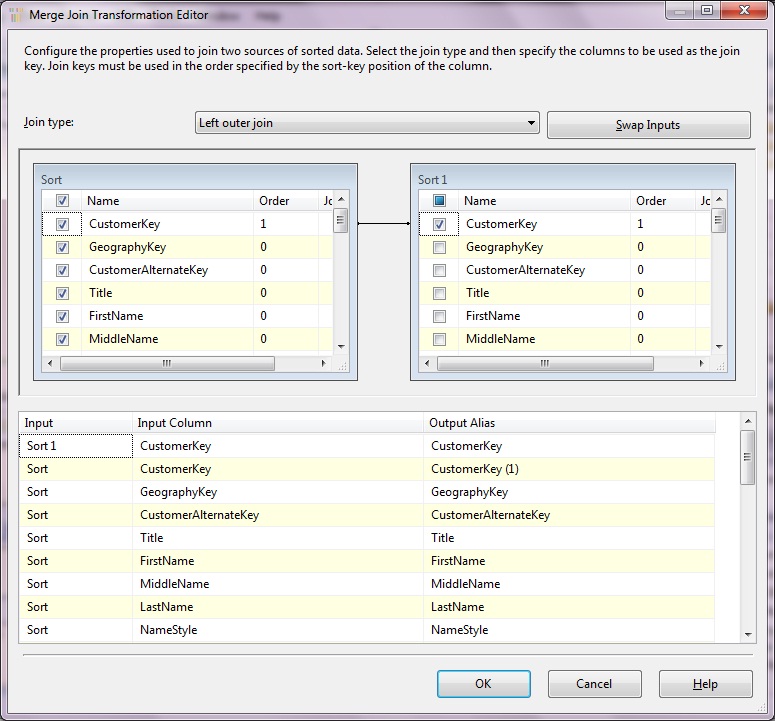
And the properties window looks like this, here we need to set which type of Join we need to perform the dataset(Left outer, right outer or inner) it’s the same what we use in any RDBMS.
UNION ALL:
The Union All transformation combines multiple inputs into one output. For example, the outputs from five different Flat File sources can be inputs to the Union All transformation and combined into one output.
The transformation inputs are added to the transformation output one after the other; no reordering of rows occurs. If the package requires a sorted output, you should use the Merge transformation instead of the Union All transformation.
The first input that you connect to the Union All transformation is the input from which the transformation creates the transformation output. The columns in the inputs you subsequently connect to the transformation are mapped to the columns in the transformation output.
To merge inputs, you map columns in the inputs to columns in the output. A column from at least one input must be mapped to each output column. The mapping between two columns requires that the metadata of the columns match. For example, the mapped columns must have the same data type.
If the mapped columns contain string data and the output column is shorter in length than the input column, the output column is automatically increased in length to contain the input column. Input columns that are not mapped to output columns are set to null values in the output columns.
This transformation has multiple inputs and one output. It does not support an error output.
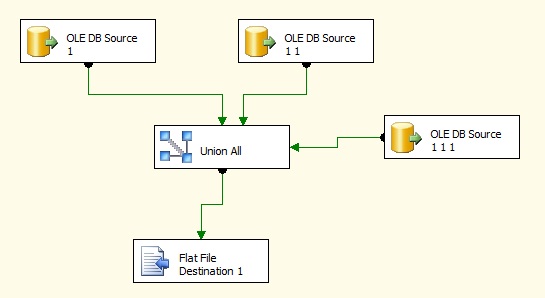
Even though I have taken all sources as OLEBD, you can take any type of source and output data to any type of destination.
Well guys that’s it for today, hope you guys have learned something.
--The Learner ..!!
Today I am going to study some of the Dataflow transformations, MERGE, MERGE JOIN, and UNION ALL.
Yes the first question any SQL SERVER developer can ask is, these operations can very well be done in T-SQL query, Why using it in SSIS?, well the answer is, T-SQL can be used only when you are working with data which resides in SQL SEVER Tables, but what if the data is coming from different database itself like ORACLE or MYSQL or Flat File or XML or EXCEL.
Let’s take it one by one each transformation, the post also covers differences, which are actually common questions, in any SSIS interviews.
Rather than reinventing the wheel, I am taking the text from MSDN for providing the description of each transformation which I found covering everything J
MERGE:
The Merge transformation combines two sorted datasets into a single dataset. The rows from each dataset are inserted into the output based on values in their key columns.
By including the Merge transformation in a data flow, you can perform the following tasks:
- Merge data from two data sources, such as tables and files.
- Create complex datasets by nesting Merge transformations.
- Remerge rows after correcting errors in the data.
The Merge transformation is similar to the Union All transformations. Use the Union All transformation instead of the Merge transformation in the following situations:
- The transformation inputs are not sorted.
- The combined output does not need to be sorted.
- The transformation has more than two inputs.
Well here is the example..here we are taking input from two different sql server databases and merging them into a flatfile.
And here is what we need to set in Merge Transformation properties
This transformation is pretty simple and straight forward.
MERGE JOIN: The Merge Join transformation provides an output that is generated by joining two sorted datasets using a FULL, LEFT, or INNER join. For example, you can use a LEFT join to join a table that includes product information with a table that lists the country/region in which a product was manufactured. The result is a table that lists all products and their country/region of origin. For more information, see Using Joins.
You can configure the Merge Join transformation in the following ways:
- Specify the join is a FULL, LEFT, or INNER join.
- Specify the columns the join uses.
- Specify whether the transformation handles null values as equal to other nulls.
| Note |
| If null values are not treated as equal values, the transformation handles null values like the SQL Server Database Engine does. |
This transformation has two inputs and one output. It does not support an error output.
Here is the same example with merge join..
And the properties window looks like this, here we need to set which type of Join we need to perform the dataset(Left outer, right outer or inner) it’s the same what we use in any RDBMS.
UNION ALL:
The Union All transformation combines multiple inputs into one output. For example, the outputs from five different Flat File sources can be inputs to the Union All transformation and combined into one output.
The transformation inputs are added to the transformation output one after the other; no reordering of rows occurs. If the package requires a sorted output, you should use the Merge transformation instead of the Union All transformation.
The first input that you connect to the Union All transformation is the input from which the transformation creates the transformation output. The columns in the inputs you subsequently connect to the transformation are mapped to the columns in the transformation output.
To merge inputs, you map columns in the inputs to columns in the output. A column from at least one input must be mapped to each output column. The mapping between two columns requires that the metadata of the columns match. For example, the mapped columns must have the same data type.
If the mapped columns contain string data and the output column is shorter in length than the input column, the output column is automatically increased in length to contain the input column. Input columns that are not mapped to output columns are set to null values in the output columns.
This transformation has multiple inputs and one output. It does not support an error output.
Even though I have taken all sources as OLEBD, you can take any type of source and output data to any type of destination.
Well guys that’s it for today, hope you guys have learned something.
--The Learner ..!!
too good
ReplyDeleteHi Manoj,
DeleteYou can access more articles at my new web address @ www.aboutsql.in
Let me know your views on the same.
Thanks
good one
ReplyDeleteWhich Input data is used for the Output, when the data is different in the two Inputs? And can you control which is used for the Output?
ReplyDeleteFor example I'm working on an existing package that used the UNION ALL transformation and is looking up Address information from two separate tables (As UNION Input 1 and UNION Input 2).
Both input tables have Addr1, Addr2, City, State, etc ... but sometimes the addresses are different.
How does the UNION transformation decide which address info (from which Input table), to use for the Output ...and is there a way to Control this?
I would like to force the UNION to take the Address info from Input 2 if it is not Null, otherwise take the Address info from Input 1.
Thanks!
And while this may seems like a mis-use of the UNION (why use it to pull the same kind of data from two different tables), the way this is being used is this ...
ReplyDeleteWe have a Patient Demographic table, Patient Address table, and Patient Insurance table.
We are pulling Patient demographic data, and if they have an Insurance record then pull that data as well and the address from the Insurance table.
If not Insurance record, then pull address data from the Address table.
So some common demographic data is being passed into the UNION, along with Input 1 (from when a patient had Insurance and that address data coming in), and from Input 2 (if no Insurance record then address data is pulled from Address table) ... and these address fields are the two Inputs to be merged with the UNION
How does the UNION decide which of the two inputs to use for the Output, and is there a way I can control which input data is used?
One Question.
ReplyDeletewhat is the Difference between UnionAll and Merge Transformation ??
Merge is to merge two sorted inputs into a single resultset, while UnionAll can take more the two inputs (not necessarily sorted).
DeleteHi Kutub, why do we need to use Merge when we have the same functionality in Union all and with less overhead than Merge(by not sorting the data before)?
ReplyDeleteNice article
ReplyDeleteNice article.
ReplyDeletePlease note your page is refreshing at small intervals
5s load page 1 times OMG
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteThat’s a very good article posted by the blogger and I think it was very good for beginners like me since I recently learned SQL and wanted to properly learn the functions of JOIN and UNION.I also have a good post for SSIS Insert or Update functions.
ReplyDelete